IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR) 2022 (Oral)
Abstract
Temporal alignment of fine-grained human actions in videos is important for numerous applications in computer vision, robotics, and mixed reality. State-of-the-art methods directly learn image-based embedding space by leveraging powerful deep convolutional neural networks. While being straightforward, their results are far from satisfactory, the aligned videos exhibit severe temporal discontinuity without additional post-processing steps. The recent advancements in human body and hand pose estimation in the wild promise new ways of addressing the task of human action alignment in videos. In this work, based on off-the-shelf human pose estimators, we propose a novel context-aware self-supervised learning architecture to align sequences of actions. We name it CASA. Specifically, CASA employs self-attention and cross-attention mechanisms to incorporate the spatial and temporal context of human actions, which can solve the temporal discontinuity problem. Moreover, we introduce a self-supervised learning scheme that is empowered by novel 4D augmentation techniques for 3D skeleton representations. We systematically evaluate the key components of our method. Our experiments on three public datasets demonstrate CASA significantly improves phase progress and Kendall's Tau scores over the previous state-of-the-art methods.
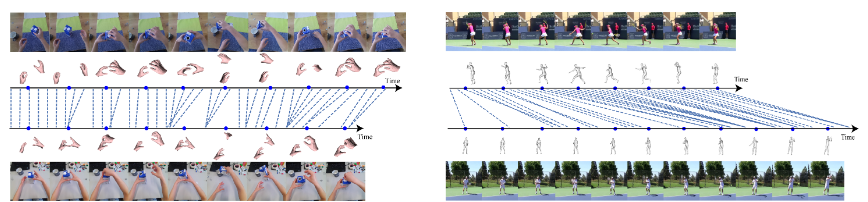
 Sequence alignment results (baseball swing).
The seven sequences are aligned with each frame (skeleton) from the reference sequence
by the nearest neighbor search in our trained embedding space.
Sequence alignment results (baseball swing).
The seven sequences are aligned with each frame (skeleton) from the reference sequence
by the nearest neighbor search in our trained embedding space.
Pipeline Overview
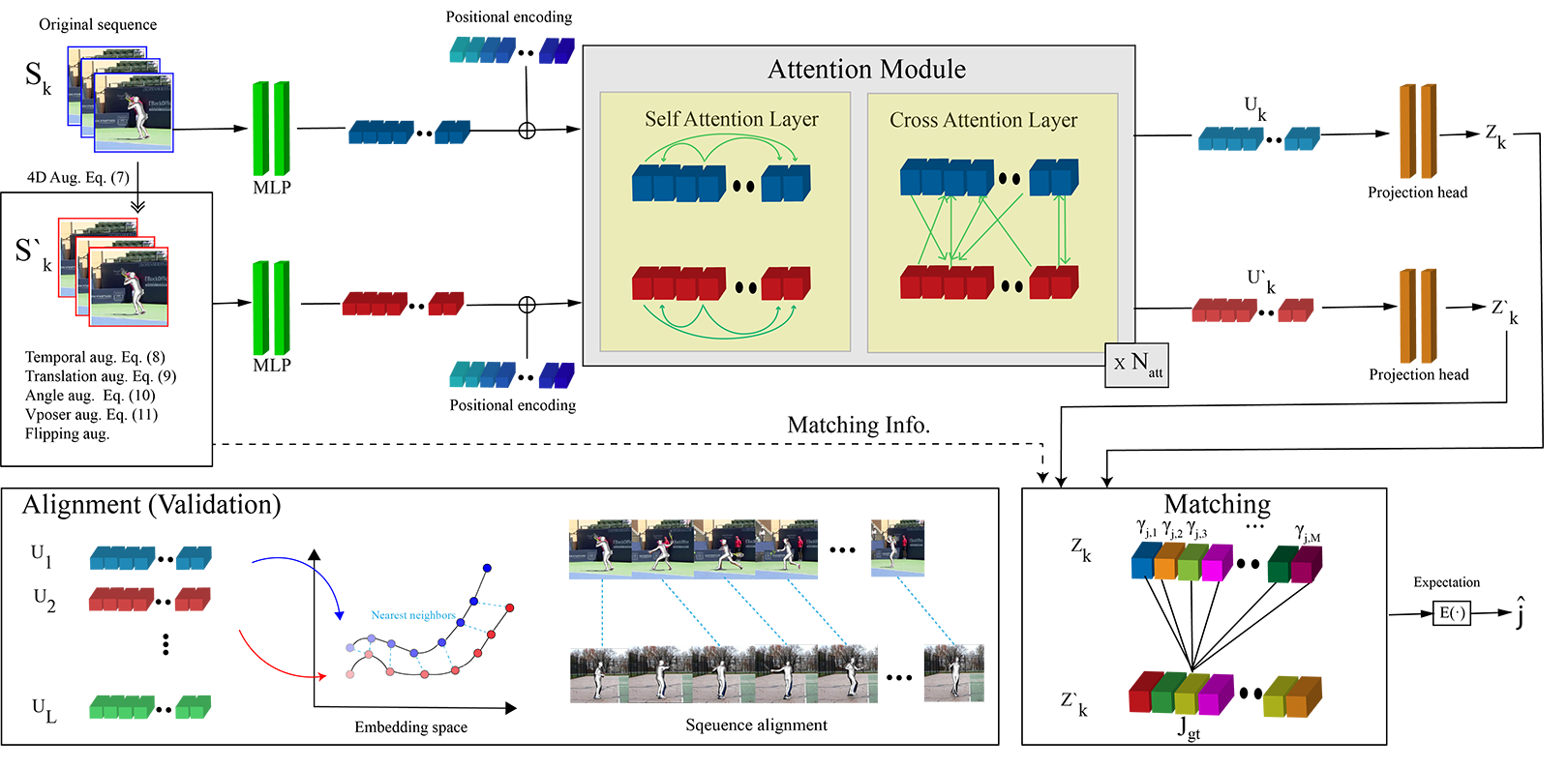
The proposed framework takes as input a skeleton sequence Sk along with its spatio-temporally augmented version S′k. Both sequences are encoded by temporal positional encodings. Self- and cross-attentional layers learn contextual information within and across sequences with the help of temporal positional encoding. We employ a projection head to improve our representation quality. We use a contrastive regression loss that matches a pose sequence with its 4D augmented version. For the downstream tasks and alignment, we use the embeddings before the projection head stage.
Sequence Alingment Results (without post-processing)
Using an attention-based architecture, our method gathers contextual information from the whole sequence during alignment which results in superior performance than previous approaches that rely on only local context. For online applications, the assumption of having the full sequence will not be valid. Therefore, we also provide results for online sequence alignment.


Additional Sequence Alignment Results
We additionally show the sequence alignment results on the H2O dataset using hand skeletons.

Video
Supplementary Video
Citation
Context-Aware Sequence Alignment using 4D Skeletal Augmentation
Taein Kwon, Bugra Tekin, Siyu Tang, Marc Pollefeys
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022
@InProceedings{Kwon_2022_CVPR,
author = {Kwon, Taein and Tekin, Bugra and Tang, Siyu and Pollefeys, Marc},
title = {Context-Aware Sequence Alignment Using 4D Skeletal Augmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {8172-8182}
}
Team
 |
 |
 |
 |
|---|---|---|---|
| Taein Kwon | Bugra Tekin | Siyu Tang | Marc Pollefeys |