|
I am a Research Scientist at Meta Reality Labs in Zurich since 2025. My research interests include Egocentric Vision, Embodied AI, Action Recognition, Multimodal Foundation Models, Contextual AI, Hand-object Interaction, Video Understanding, AR/VR, Multi-modal Learning, Visual-language Models and Self-supervised Learning. Previously, I was a postdoctoral research fellow at VGG @ University of Oxford working with Prof. Andrew Zisserman (2024-2025). Also, I completed my PhD at ETH Zurich under the supervision of Prof. Marc Pollefeys in 2024 and my Master’s degree at UCLA in 2018. If you are interested in collaboration with me, feel free to email me. We can discuss potential exciting projects. |

|
|
|

|
Alyssa Chan*, Taein Kwon*, Andrew Zisserman arXiv, 2026 project page / paper / code In this work, we introduce a new large-scale BSL fingerspelling dataset, FS23K, constructed using an iterative annotation framework. In addition, we propose a fingerspelling recognition model that explicitly accounts for bi-manual interactions and mouthing cues. * co-first authors |
|
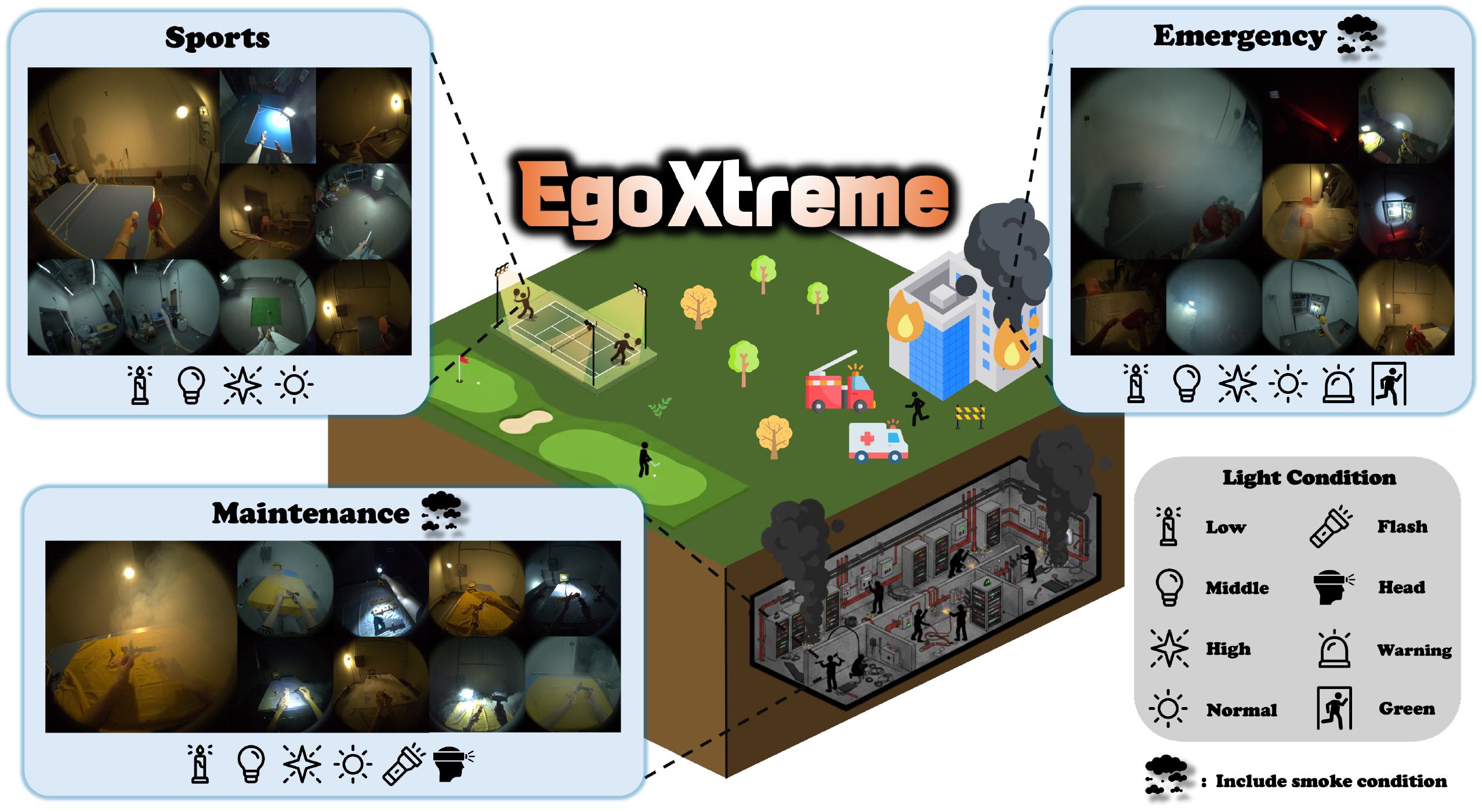
Taegyoon Yoon, Yegyu Han, Seojin Ji, Jaewoo Park, Sojeong Kim, Taein Kwon**, Hyung-Sin Kim**, CVPR, 2026 (Highlight) project page / paper / code EgoXtreme is a novel, large-scale dataset designed for robust egocentric 6D object pose estimation under extreme conditions. Specifically, 8 illumination conditions are used across three scenarios, and smoke is included in specific scenes. These conditions, combined with severe motion blur, make accurate 6D object pose estimation extremely challenging. ** co-supervision and corresponding authors. |
|
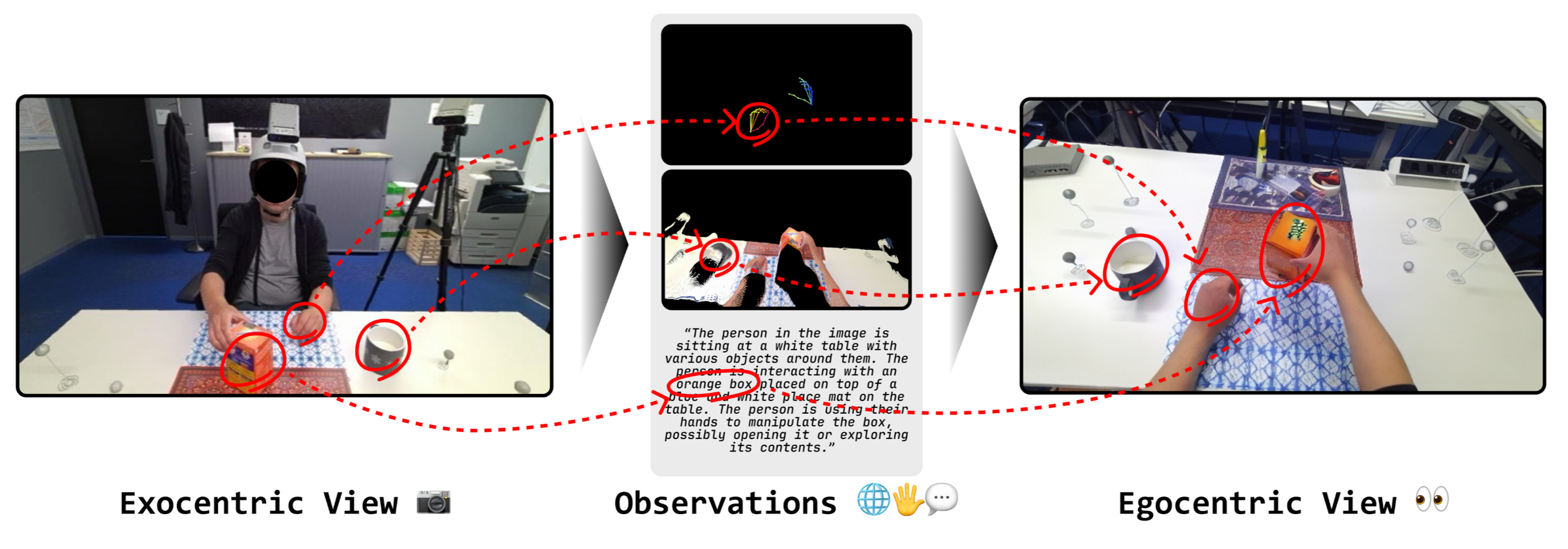
Junho Park, Andrew Sangwoo Ye, Taein Kwon ICLR, 2026 project page / paper We introduce EgoWorld, a novel two-stage framework that reconstructs egocentric view from rich exocentric observations, including depth maps, 3D hand poses, and textual descriptions. |

|
Sindhu Hggde*, K R Prajwal*, Taein Kwon, Andrew Zisserman ICCV, 2025 (Oral) project page / paper / code We introduce JEGAL, a Joint Embedding space for Gestures, Audio and Language. Our semantic gesture representations can be used to perform multiple downstream tasks such as cross-modal retrieval, spotting gestured words, and identifying who is speaking solely using gestures. * co-first authors |

|
Yiming Zhao*, Taein Kwon*, Paul Streli*, Marc Pollefeys, Christian Holz CVPR, 2025 (Highlight) project page / paper We introduce EgoPressure, a novel dataset of touch contact and pressure interaction from an egocentric perspective, complemented with hand pose meshes and fine-grained pressure intensities for each contact. * co-first authors |
|
Taein Kwon, Zador Pataki, Mahdi Rad, Marc Pollefeys arXiv, 2025 paper We propose a novel framework that overcomes these limitations using sequence alignment via implicit clustering. Specifically, our key idea is to perform implicit clip-level clustering while aligning frames in sequences. This coupled with our proposed dual augmentation technique enhances the network's ability to learn generalizable and discriminative representations. |

|
Xin Wang*, Taein Kwon*, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Ashley Fanello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, Marc Pollefeys ICCV, 2023 (EgoVis Distinguished Paper Award) project page / paper / supp HoloAssist is a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. * co-first authors |
|
Junan Lin*, Zhichao Sun*, Enjie Cao*, Taein Kwon, Mahdi Rad, Marc Pollefeys arXiv, 2023 paper Contact-aware Skeletal Action Recognition (CaSAR) uses novel representations of hand-object interaction that encompass spatial information: 1) contact points where the hand joints meet the objects, 2) distant points where the hand joints are far away from the object and nearly not involved in the current action. Our framework is able to learn how the hands touch or stay away from the objects for each frame of the action sequence, and use this information to predict the action class. * co-first authors |

|
Siwei Zhang, Qianli Ma, Yan Zhang, Zhiyin Qian, Taein Kwon, Marc Pollefeys, Federica Bogo, Siyu Tang ECCV, 2022 project page / paper / code EgoBody is a large-scale dataset of accurate 3D human body shape, pose and motion of humans interacting in 3D scenes, with multi-modal streams from third-person and egocentric views, captured by Azure Kinects and a HoloLens2. Given two interacting subjects, we leverage a lightweight multi-camera rig to reconstruct their 3D shape and pose over time. |
|
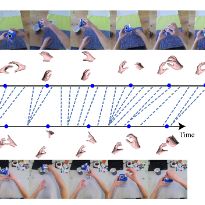
Taein Kwon, Bugra Tekin, Siyu Tang, Marc Pollefeys CVPR, 2022 (Oral) project page / paper / video / code We propose a skeletal self-supervised learning approach that uses alignment as a pretext task. Our approach to alignment relies on a context-aware attention model that incorporates spatial and temporal context within and across sequences and a contrastive learning formulation that relies on 4D skeletal augmentations. Pose data provides a valuable cue for alignment and downstream tasks, such as phase classification and phase progression, as it is robust to different camera angles and changes in the background, while being efficient for real-time processing. |

|
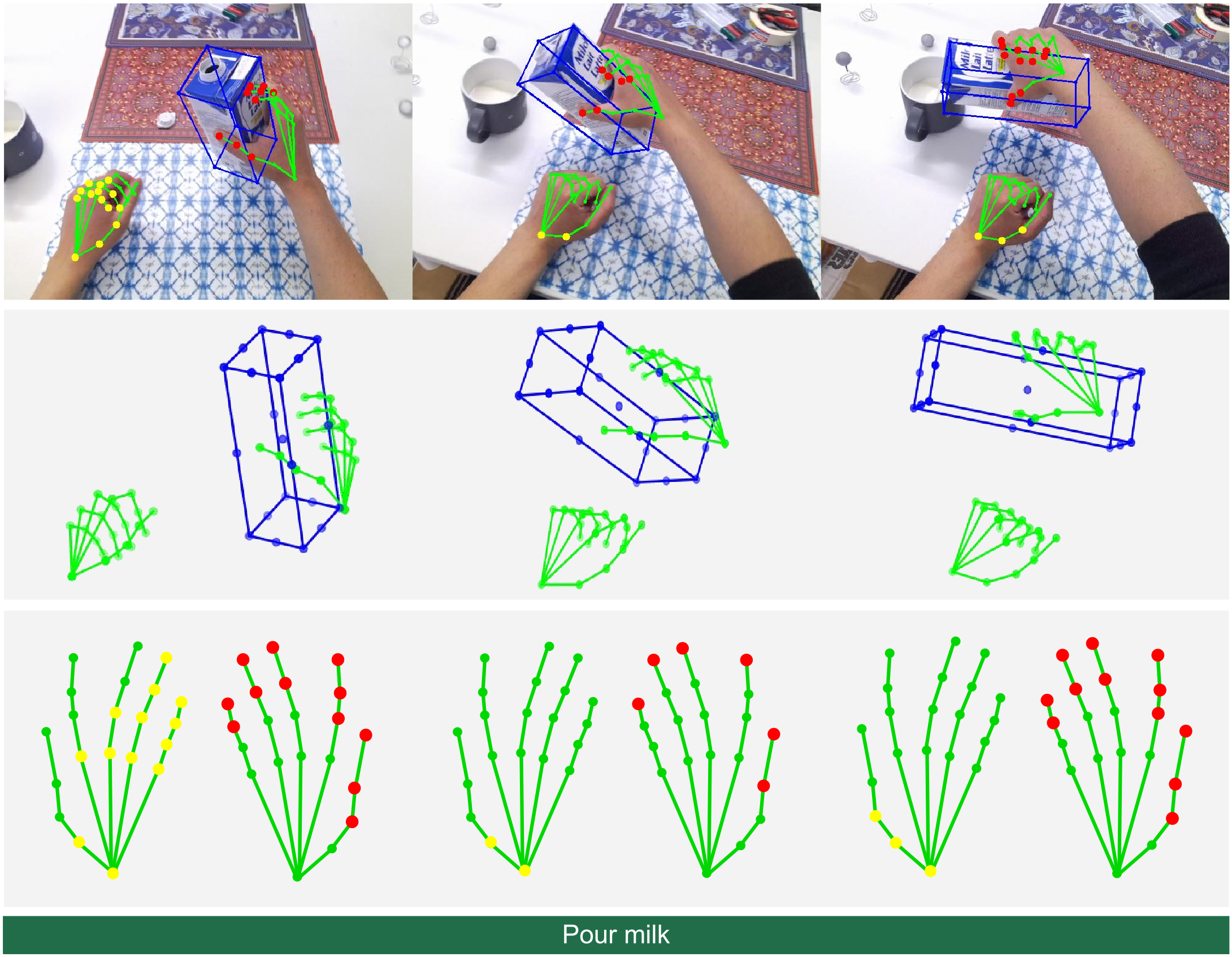
Taein Kwon, Bugra Tekin, Jan Stuhmer, Federica Bogo, Marc Pollefeys ICCV, 2021 project page / paper / video In this paper, we propose a method to collect a dataset of two hands manipulating objects for first person interaction recognition. We provide a rich set of annotations including action labels, object classes, 3D left & right hand poses, 6D object poses, camera poses and scene point clouds. We further propose the first method to jointly recognize the 3D poses of two hands manipulating objects and a novel topology-aware graph convolutional network for recognizing hand-object interactions. |
|
|
|
|
|
|
taeinkwon90@gmail (dot) com |
|
Website template from Jon Barron. |